家里有一台win7系统的电脑,平时可以用来玩玩游戏消磨时间。但是有时候有一些重复的操作实在是无趣,所以打算写个脚本,让其自动化执行。
最终的目标就是把游戏里一些常用的操作都集合到脚本中去,且无序随机执行,模拟真人操作。点击此处查看原文。
大漠插件介绍
因为使用的是Windows系统,所以好多工作之前已经有大佬完成了。几年前使用过按键精灵的同学一定对大漠插件不陌生,其功能之强大,可以用来完成很多操作。
从文档可以看出,功能实在太多了,覆盖了方方面面。我基本使用到的就是图片识别,文字识别,键鼠操作等,最强大的功能莫过于后台操作,也就是窗口最小化时不影响鼠标键盘的操作。想象一下,游戏在后台自动执行,前台继续做工作,互不干扰。
我现在需要做的就是将大漠插件使用python而不是按键精灵让其工作,因为按键精灵这类软件很容易被查出来。
文字识别
图像转文字需要三个步骤。
- 拿到图片
- 二值化
- 使用字库进行识别
图像转文字需要三个步骤。
- 拿到图片
- 二值化
- 使用字库进行识别
当这三步完成的时候,文字顺理成章就被识别出来了。
使用大漠插件的好处是每次识别不需要将识别的图片保存到本地,而是给定屏幕上的范围就可以识别了。
现在我们按步骤操作一波。
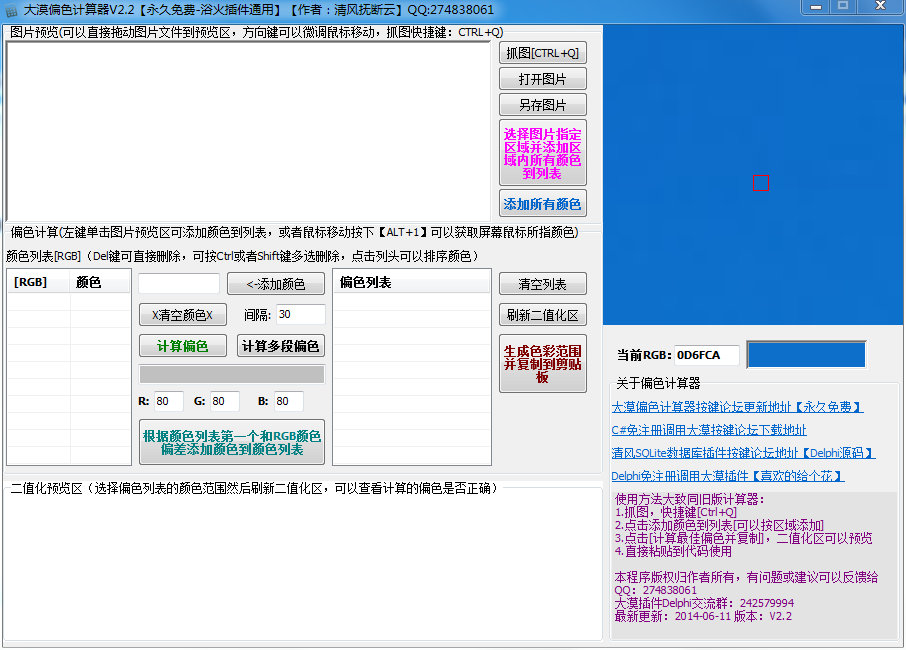
拿到图片,获取偏色列表

我们需要识别这张图片中的“3”,“0”,“/”,“2”,“7”。
使用大漠偏色计算器计算偏色。
具体步骤是:
- 先抓图,获取图片
- 识别数字。将鼠标移到需要识别的数字的颜色部分(例如这个图片背景是棕色,文字是黑色,将鼠标移到黑色部分,稍后的二值化就是将黑色部分突出显示)。
- 点击“根据颜色列表的第一个和RGB颜色偏差添加颜色到颜色列表”,会自动生成多个颜色。
- 点击计算偏色。
二值化预览区应该可以清晰的看到我们需要识别的数字了。
具体顺序可以配合着这张图:
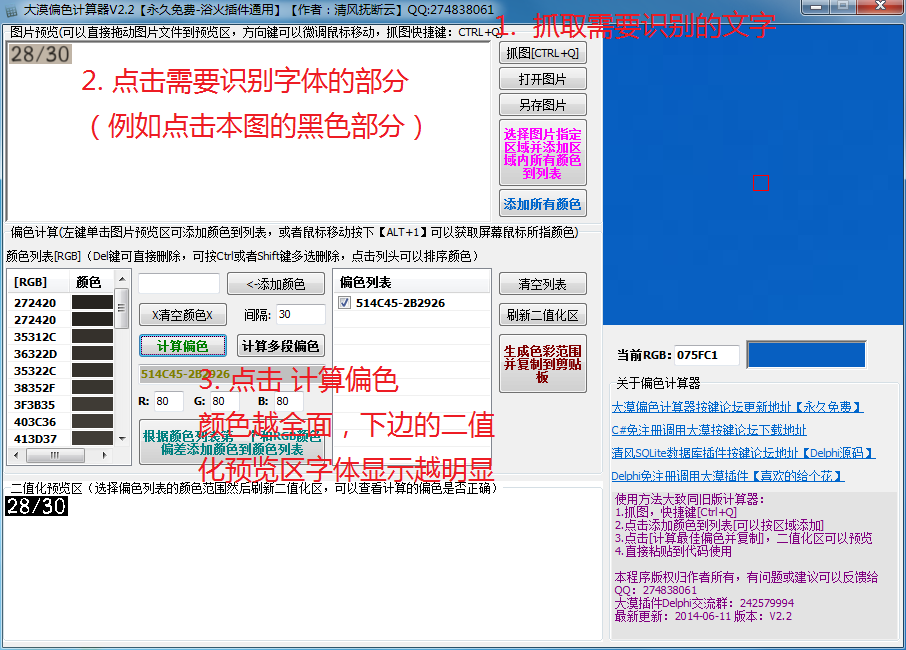
如果你觉得识别后的文字还不够清晰,可以自己修改颜色列表。
这一步操作我们需要拿到偏色列表:514C45-2B2926。这个偏色列表之后用处非常大。
使用大漠综合工具新建或编辑字库
二值化显示的结果,程序还是不认识“3”或“0”,需要我们告诉程序,“3”这个字符对应的是数字3,这样当我们之后识别字符,程序再遇到“3”样子的字符就会返回3这个数字。
提取点阵并定义文字,将识别后的结果与我们想要的结果做对应,然后添加到字库。
简单描述我们的操作是:
- 使用浮动抓图功能,在桌面上找到需要识别的范围
- 在第一行RGB,偏色输入刚才的偏色列表
- 点击提取点阵(多个)
- 打开或新建字库(txt文件)
- 定义文字(然后回车)
配合图片解释一波:

需要注意的是在提取点阵的时候弹出一个对话框,直接按确认就可以。
如果遇到一个预览结果显示多个字符,两个字符被认为是一个字符的情况,可能是偏色列表不够严谨,重新在判断偏色吧。
预览结果是“0”,那么就在定义文字一栏输入0,回车,这样就做了对应,并保存到字库中了。
重复以上操作,把需要识别的字符都做对应。当然我介绍的是对于游戏中一些特殊字符,系统无法识别需要自己做对应。大漠插件有提供系统字体的字库,也比较丰富,不一定必须自己造字库。
配合python返回识别结果
前面做了这么多工作,说到底还是为了python做准备。
使用32的python
如果你的电脑里已经有了python,不好意思,可能需要重装。因为调用大漠插件只能使用python 32位的,不限制python2或3。我使用的是python3.7版本的32位。64位会报错。
安装pywin32库
安装好32位的python后,安装pywin32库来操作大漠插件。
命令行输入pip install pywin32,等待安装完成。
注册大漠插件
下载好大漠插件压缩包后,需要注册大漠插件。
在dm.dll文件的同目录中,使用管理员权限在cmd里执行:
regsvr32 dm.dll
完成注册。
demo
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import win32com.client
class DmBase(object):
def __init__(self):
# 调用大漠插件
self.dm = win32com.client.Dispatch(\"dm.dmsoft\")
# 设定字库文件,建议在初始化中调用,比较耗时
self.dm.setDict(0, \"C:\\\\Users\\\\Li\\\\Desktop\\\\help\\\\data\\\\num.txt\")
# 使用字库
self.dm.useDict(0)
def ocr(self, x1, y1, x2, y2, color_format, sim=0.9):
\"\"\"
文字识别
- Args:
x1 (int): 左上x
y1 (int): 左上y
x2 (int): 右下x
y2 (int): 右下y
color_format (str): 偏色列表
sim (float): 相似度,范围 0.1-1.0
- Return:
识别的字符串
\"\"\"
return self.dm.Ocr(x1, y1, x2, y2, color_format, sim)
如果你的电脑里已经有了python,不好意思,可能需要重装。因为调用大漠插件只能使用python 32位的,不限制python2或3。我使用的是python3.7版本的32位。64位会报错。
安装pywin32库
安装好32位的python后,安装pywin32库来操作大漠插件。
命令行输入pip install pywin32,等待安装完成。
注册大漠插件
下载好大漠插件压缩包后,需要注册大漠插件。
在dm.dll文件的同目录中,使用管理员权限在cmd里执行:
regsvr32 dm.dll
完成注册。
demo
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import win32com.client
class DmBase(object):
def __init__(self):
# 调用大漠插件
self.dm = win32com.client.Dispatch(\"dm.dmsoft\")
# 设定字库文件,建议在初始化中调用,比较耗时
self.dm.setDict(0, \"C:\\\\Users\\\\Li\\\\Desktop\\\\help\\\\data\\\\num.txt\")
# 使用字库
self.dm.useDict(0)
def ocr(self, x1, y1, x2, y2, color_format, sim=0.9):
\"\"\"
文字识别
- Args:
x1 (int): 左上x
y1 (int): 左上y
x2 (int): 右下x
y2 (int): 右下y
color_format (str): 偏色列表
sim (float): 相似度,范围 0.1-1.0
- Return:
识别的字符串
\"\"\"
return self.dm.Ocr(x1, y1, x2, y2, color_format, sim)
下载好大漠插件压缩包后,需要注册大漠插件。
在
dm.dll文件的同目录中,使用管理员权限在cmd里执行:regsvr32 dm.dll完成注册。
demo
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import win32com.client
class DmBase(object):
def __init__(self):
# 调用大漠插件
self.dm = win32com.client.Dispatch(\"dm.dmsoft\")
# 设定字库文件,建议在初始化中调用,比较耗时
self.dm.setDict(0, \"C:\\\\Users\\\\Li\\\\Desktop\\\\help\\\\data\\\\num.txt\")
# 使用字库
self.dm.useDict(0)
def ocr(self, x1, y1, x2, y2, color_format, sim=0.9):
\"\"\"
文字识别
- Args:
x1 (int): 左上x
y1 (int): 左上y
x2 (int): 右下x
y2 (int): 右下y
color_format (str): 偏色列表
sim (float): 相似度,范围 0.1-1.0
- Return:
识别的字符串
\"\"\"
return self.dm.Ocr(x1, y1, x2, y2, color_format, sim)
# -*- coding: utf-8 -*-
import win32com.client
class DmBase(object):
def __init__(self):
# 调用大漠插件
self.dm = win32com.client.Dispatch(\"dm.dmsoft\")
# 设定字库文件,建议在初始化中调用,比较耗时
self.dm.setDict(0, \"C:\\\\Users\\\\Li\\\\Desktop\\\\help\\\\data\\\\num.txt\")
# 使用字库
self.dm.useDict(0)
def ocr(self, x1, y1, x2, y2, color_format, sim=0.9):
\"\"\"
文字识别
- Args:
x1 (int): 左上x
y1 (int): 左上y
x2 (int): 右下x
y2 (int): 右下y
color_format (str): 偏色列表
sim (float): 相似度,范围 0.1-1.0
- Return:
识别的字符串
\"\"\"
return self.dm.Ocr(x1, y1, x2, y2, color_format, sim)
这样就完成了python调用大漠插件识别文字的操作。
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!603313839@qq.com
2. 请您必须在下载后的24个小时之内,从您的电脑中彻底删除上述内容资源
3. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
4. 不保证所提供下载的资源的准确性、安全性和完整性,源码仅供下载学习之用!
5. 不保证所有资源都完整可用,不排除存在BUG或残缺的可能,由于资源的特殊性,下载后不支持退款。
6. 站点所有资源仅供学习交流使用,切勿用于商业或者非法用途,与本站无关,一切后果请用户自负!